안녕하세요! 제이덥입니다. 최근에는 Dacon 대회에 참여하여 특정 도메인에 적합한 LLM(Large Language Model)을 구축하는 Task를 진행했습니다. 이 과정에서 구축한 모델의 평가지표로 코사인 유사도(Cosine Similarity)를 사용했습니다. 코사인 유사도의 기본 개념은 이해하고 있었지만, 언어모델을 평가할 때 구체적으로 어떤 의미를 가지는지 명확히 알지 못했습니다. 따라서, 코사인 유사도가 무엇인지, 언어모델을 평가할 때의 장점 및 한계점은 어떻게 되는지 이번 포스팅을 통해 정리해보고자 합니다.
1️⃣ 코사인 유사도란
코사인 유사도(― 類似度, 영어: cosine similarity)는 내적공간의 두 벡터간 각도의 코사인값을 이용하여 측정된 벡터간의 유사한 정도를 의미합니다.(출처 위키피디아). 정확하게 말하면 벡터간의 방향성의 유사도를 체크해주는 평가지표로 두 벡터간의 각도가 0일 때 1, 직교할 때 0, 방향이 반대일 경우(180도) -1의 값을 갖습니다. 즉, -1 ~ 1 사이에 값을 가지며 1에 가까울 수록 같은 방향을, -1에 가까울수록 상대적으로 반대 방향을 가르킨다는 것을 의미합니다.
유클리디안 스칼라 곱에서 벡터 a, b의 내적은 다음과 같습니다.
$$
a \cdot b = |a| |b| \cos\theta
$$
그리고 이를 이용해 $\cos\theta$를 유도 할 수 있습니다.
a, b 벡터를 $A, B$ 벡터로 치환하고 (A_i)와 (B_i)는 각각 벡터 (A)와 (B)의 (i)번째 성분으로 가정한다면 $A \cdot B$ 를 다음과 같이 정리해줄 수 있고,
$$
A \cdot B = \sum_{i=1}^{n} A_i \times B_i
$$
벡터 (A)와 (B)의 크기는 정의에 의해 각각 다음과 같이 계산됩니다:
$$
|A| = \sqrt{\sum_{i=1}^{n} (A_i)^2}, \quad |B| = \sqrt{\sum_{i=1}^{n} (B_i)^2}
$$
그리고 이를 위의 식에 정의해 정리해주면 다음 과 같이 정리해줄 수 있습니다.
$$
\text{similarity} = \cos(\theta) = \frac{A \cdot B}{|A||B|} = \frac{\sum_{i=1}^{n} A_i \times B_i}{\sqrt{\sum_{i=1}^{n} (A_i)^2} \times \sqrt{\sum_{i=1}^{n} (B_i)^2}}
$$
2️⃣ 언어 모델과 코사인 유사도
BoW에 기반한 단어 전통적인 단어 표현 방법인 DTM, TF-IDF 등을 이용하거나 단어의 의미적 유사도를 이용한 Word2Vec을 이용하여 단어를 벡터 형태로 임베딩해줄 수 있습니다. 이러한 임베딩 방식을 통해 벡터 형태로 표현된 단어는 코사인 유사도를 통해 유사도를 구해줄 수 있습니다. 하지만는 BoW, DTM, TF-IDF단어의 순서나 문맥을 고려하지 못하고, word2vec 형태로 표현된 단어는 단어끼리의 유사성을 고려하지만, 문맥적인 유사도를 이해하지 못합니다. 따라서 문장을 전통적인 방식을 통해 벡터를 표현할 경우 코사인 유사도를 통해 유사성을 측정할 경우 의미의 유사성을 찾지 못하는 한계를 가지고 있습니다.
따라서 해당 대회에서는 Sentence Transformer를 이용해서 이를 보완하려고 했습니다. Sentence Transformer는 BERT를 파인 튜닝해서 문장 자체를 고차원의 임베딩 벡터로 표현할 수 있도록 도와줍니다. BERT, RoBERTa, DistilBERT 등과 같은 사전 훈련된 Transformer 모델을 기반으로 하며, 이 모델들을 Siamese 및 Triplet 네트워크 구조와 결합하여 효율적으로 문장 임베딩을 생성합니다. 그리고 이러한 벡터를 코사인 유사도를 측정함으로써 문장의 유사도를 계산하여 얼마나 언어 모델이 의미적 유사성을 지닌 문장을 생성하는지 측정할 수 있습니다.
다음 예시에서 Hugging Face의 sentence-transformers 라이브러리 중 'distiluse-base-multilingual-cased-v1' 모델을 활용하여 측정한 문장 간의 유사도를 살펴 보겠습니다.
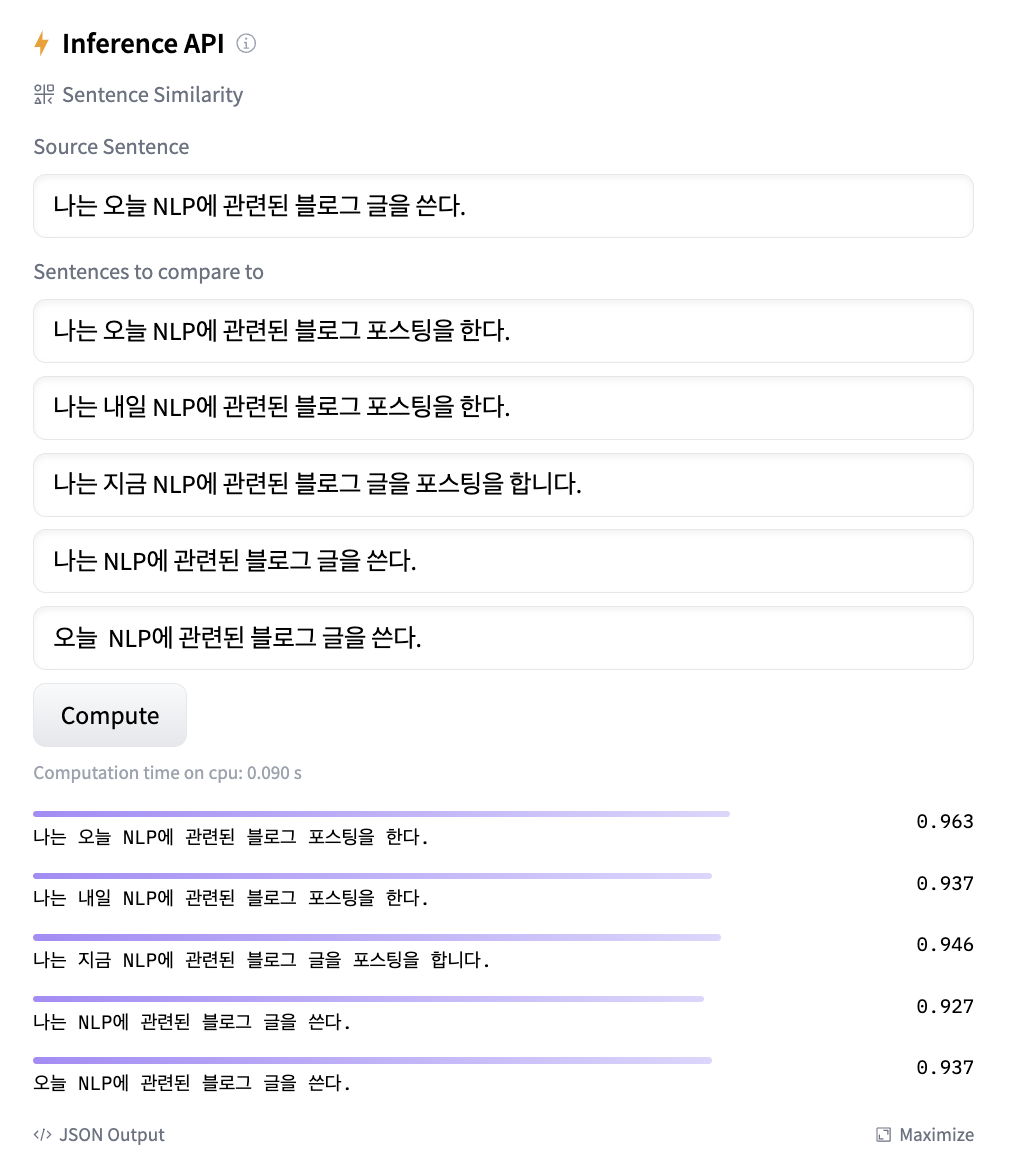
이 예시를 통해 같은 주제, 단어를 담고 있는지에 대해서는 효과적으로 동작하는 것을 볼 수 있습니다.
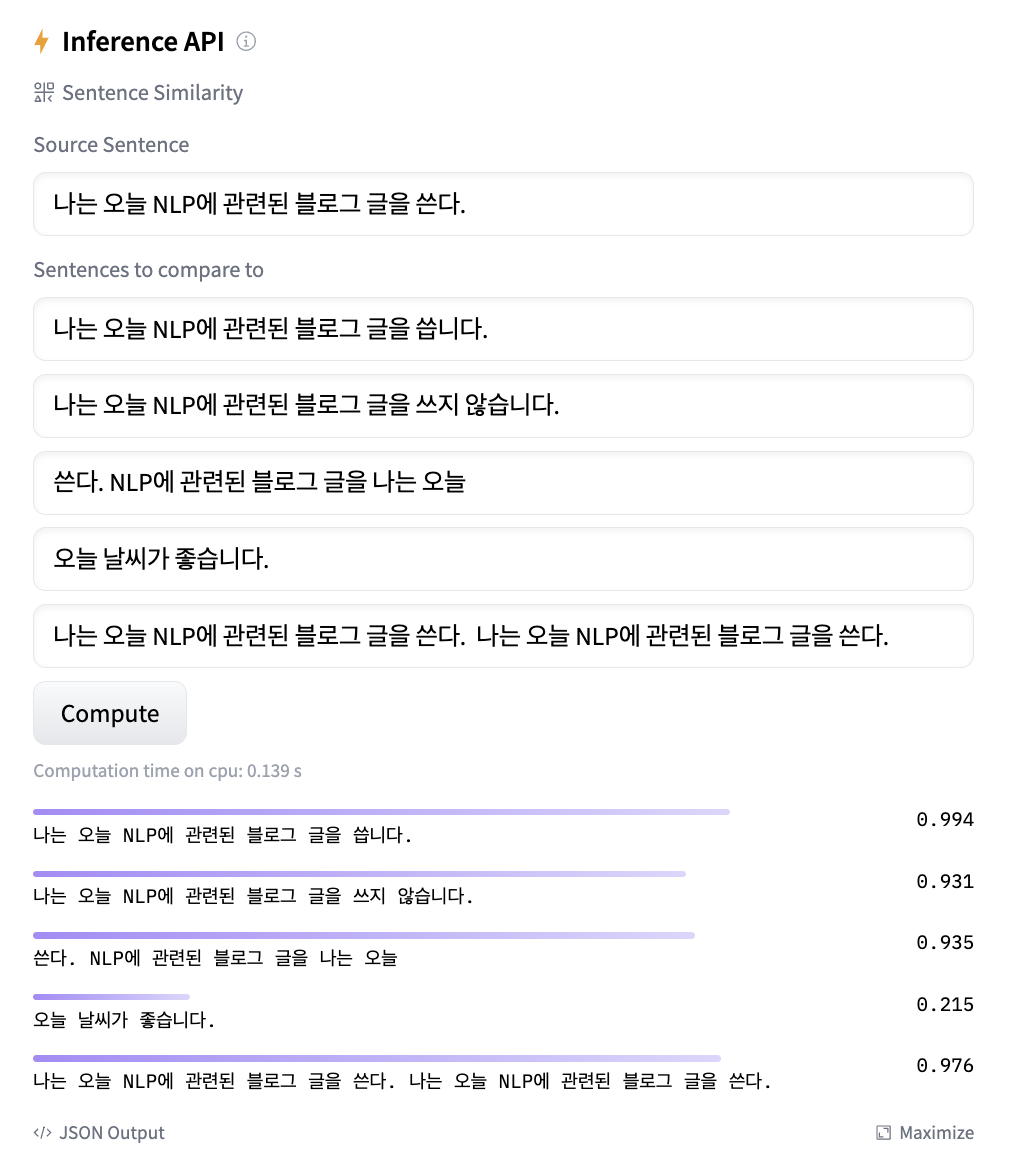
하지만 아래처럼 문장의 순서가 바뀌는 문법적인 오류가 있거나, 반복되거나, 반대의 의미를 가지는 것에 대해 효과적으로 동작을 하지 못한다는 단점이 있습니다.
정리하자면 Sentence Transformer 모델을 통해 언어 모델로 생성된 답변과 기존 데이터의 답변을 코사인 유사도를 통해 비교하는 것은 같은 주제, 내용을 담고 있는지에 대해 정량적으로 평가할 수 있지만, 문장의 완성도나 같은 주제를 담고 있을 때 반대의 의미를 효과적으로 구분하지 못한다는 단점이 있습니다.
최근 모두콘 2023에서 손규진 연사님의 “언어 모델은 어떻게 평가할까?” 강연을 들었습니다. 강연에서는 LLM 성능 평가를 위해 영어는 MMLU 한국어는 HAERAE, KMMLU 등 다양한 벤치마크가 사용되지만, 벤치마크 데이터를 단순히 변경하는 것만으로도 성능 지표가 크게 달라질 수 있다는 점에서 아직 완벽한 평가 방법은 없으며 연구가 필요한 부분이라고 이야기해주셨습니다. 이 강연을 통해, 저는 각 벤치마크의 장단점을 파악하고, 이를 보완할 수 있도록 언어 모델을 다양한 벤치마크를 사용하여 다각도에서 평가할 필요성을 느꼈습니다. 이런 맥락에서 '코사인 유사도'를 평가하자면, 지식 기반의 Task을 수행할 때, LLM 모델의 답변과 QA 데이터의 답변을 비교하여 문장이 포함하고 있는 지식의 양을 정량적으로 평가할 수 있는 장점이 있지만, 이 지표는 문장의 문법적 완성도를 평가하는 데는 한계가 있으므로 이를 보완할 수 있는 metric을 따로 활용해야겠다는 생각을 하게되었습니다.
Reference :