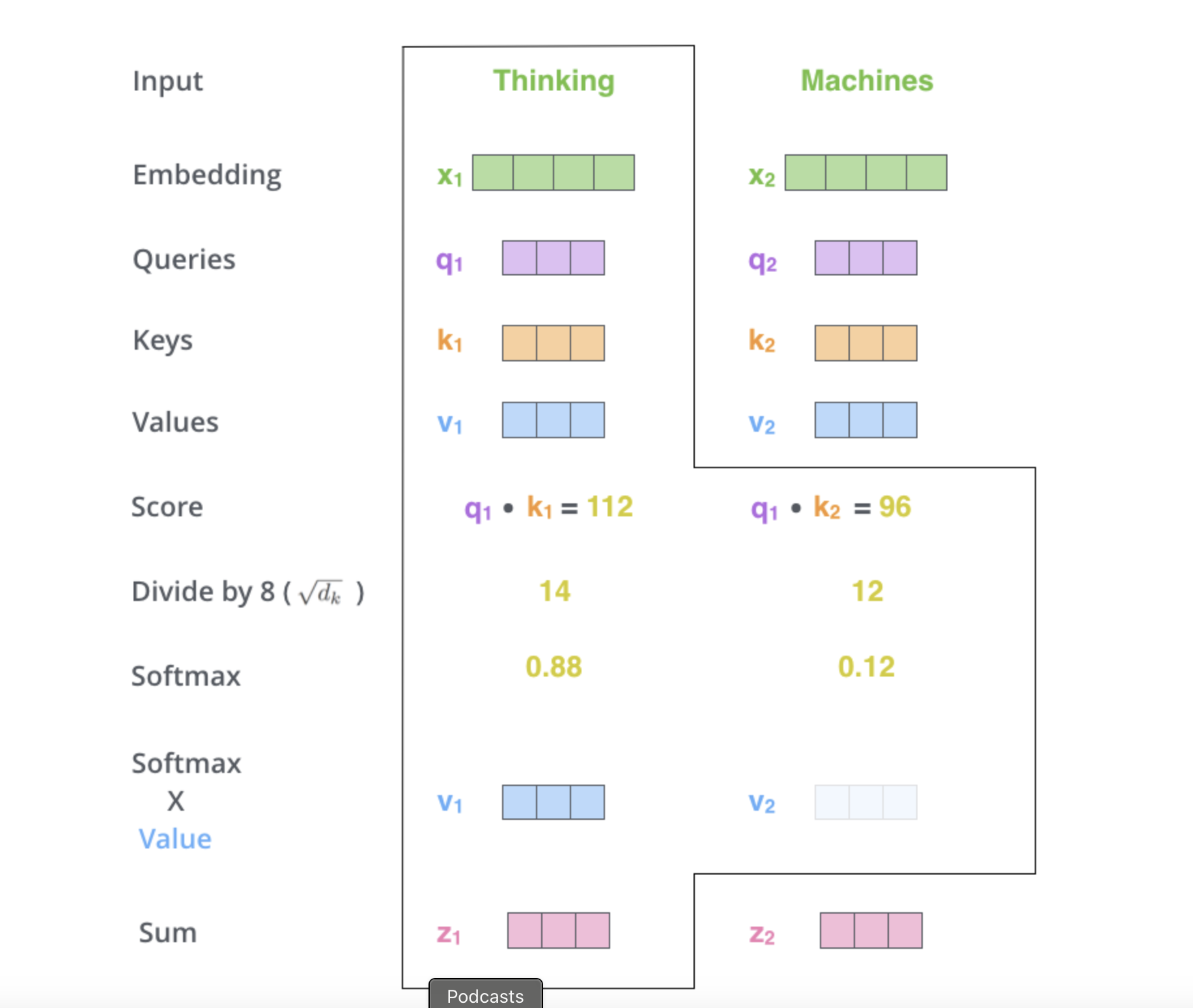
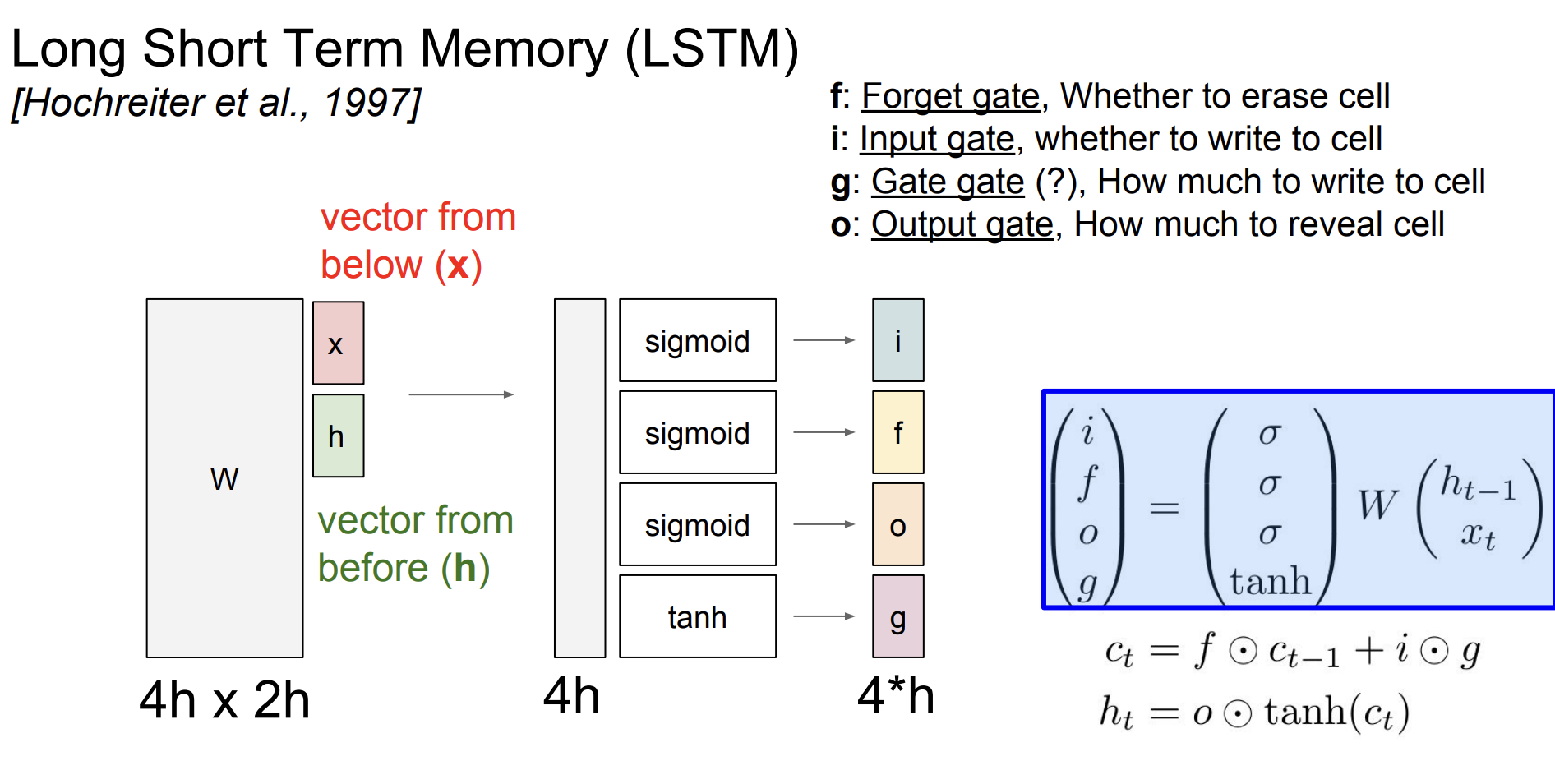
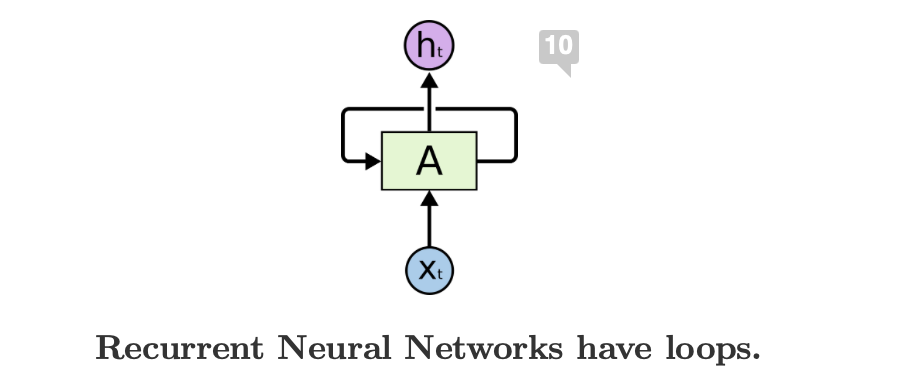
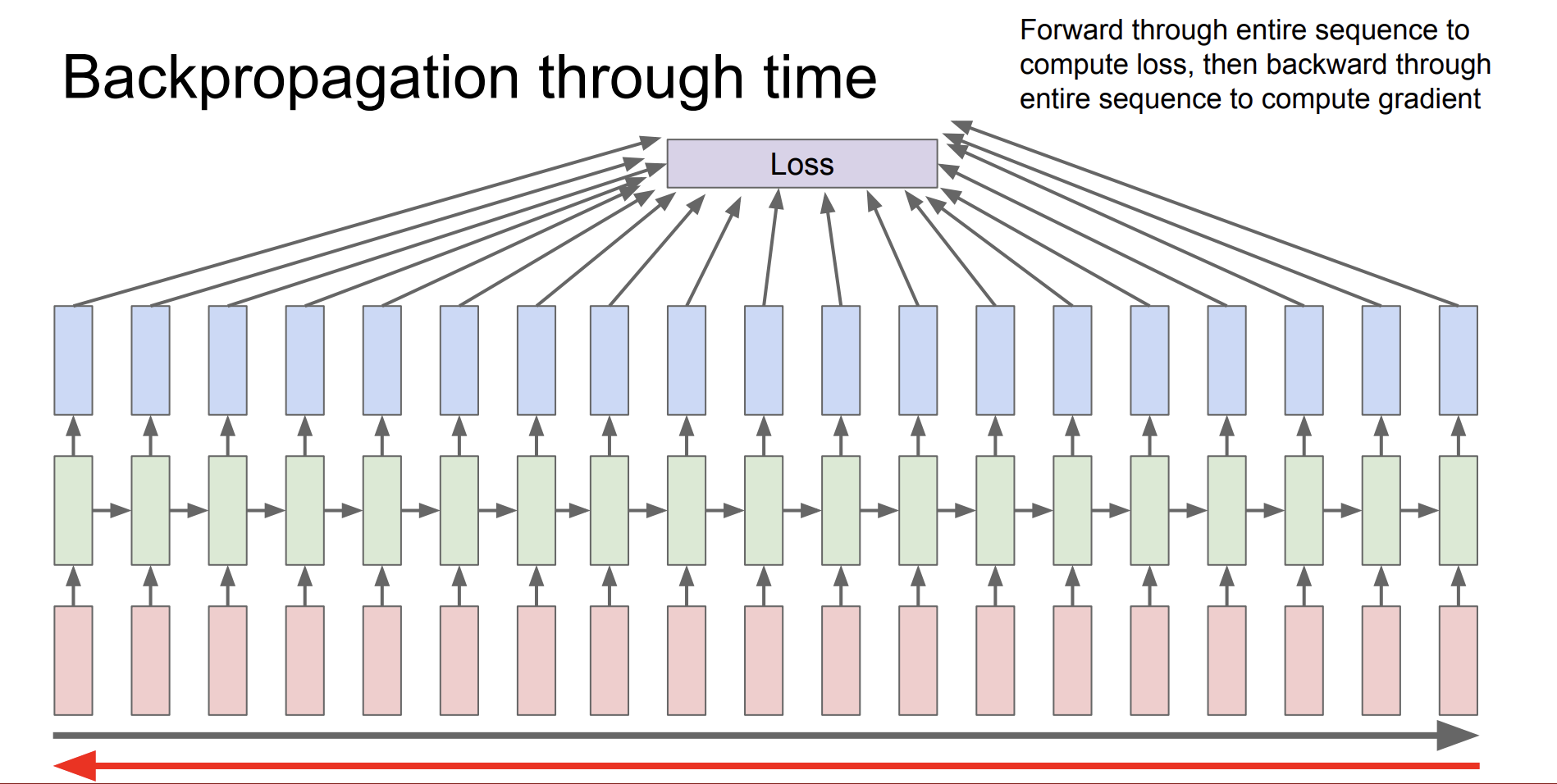
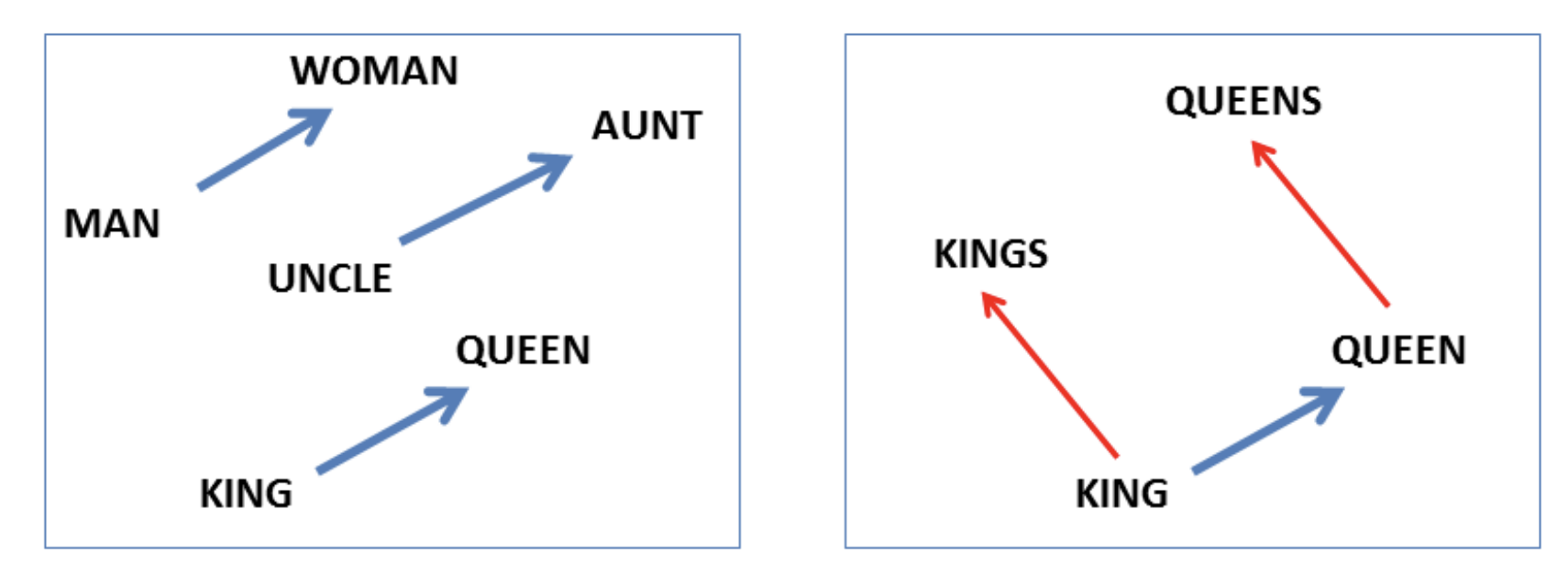
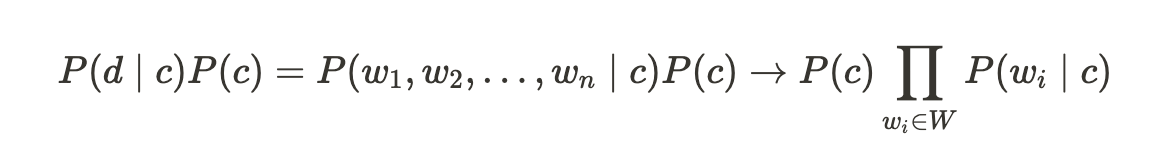안녕하세요, 제이덥입니다! 기술 면접을 준비하면서 기초 개념들을 하나씩 정리하고 있는데요. 오늘은 Transformer에 대해 다뤄보려 합니다. 이번 글에서는 Transformer의 탄생 배경이 된 Long-Term Dependency 문제를 간단히 소개하고 논문 Attention Is All You Need에서 제안된 Transformer의 작동 원리를 정리해보겠습니다. 특히 그중에서도 핵심 개념인 Self-Attention에 집중해 개념과 수식을 중심으로 깊이 있게 설명드릴 예정입니다.0️⃣ 탄생 배경 : Long-Term Dependency이전 포스팅에서 Vanilla RNN의 BPTT를 소개하면서 RNN의 Long-Term Dependency 문제에 대해서 다뤘습니다. 이 문제는 이후 Transf..