안녕하세요! 제이덥입니다. 최근에 기술 면접을 준비하며, 기초적인 내용부터 하나씩 정리하고 있는데요. 오늘은 텍스트 마이닝에서 사용하는 방법들 2가지를 정리해봤습니다. 첫 번째는 텍스트를 숫자로 표현하는 기법인 Bag Of Words(BoW) 표현형과 이를 활용한 Naive Bayes Classifier에 대해 정리해봤습니다.
1️⃣ Bag of Words (BoW)
자연어를 다루는 분야를 NLP(Natural Language Processing; 자연어처리), Text Mining(텍스트 마이닝), Information Retrieval(정보 검색)으로 나눌 수 있는데요. Bag of Words는 딥러닝 기술이 적용되기 이전 텍스트 마이닝에서 자주 사용되던 기법입니다. Bag of Words는 단어들의 순서는 고려하지 않고, 단어들의 출현 빈도만을 고려한 표현법입니다. 아래의 예를 들어 구체적인 설명을 이어 나가겠습니다. 우선 예시 문장 2개를 준비해 볼게요.
🧪 Example Sentences :
[ "Jadob loves studying Natural Language Processing", "Natural Language Processing is difficult to study"]
Step 1. 고유 단어로 된 사전 구축하기
먼저 Example Sentences에 들어가 있는 문장에서 단어를 기준으로 사전을 만듭니다. 정확한 표현은 단어를 Key 값으로 하여 중복된 Key는 나타나지 않도록 하는 집합(set)을 만들어 줍니다.
🧪 Vocabulary Set :
{ "Jadob" ,"loves" , "studying", "Natural", "Language", "Processing", "is" "difficult" "to" "study"}
*복합단어인 Natural Language Processing의 의미를 보존하고 싶다면 하나의 단어로 분류하셔도 무방합니다.
Step 2. One-Hot Encoding(원 핫 인코딩하기)
그리고 각각의 단어를 원-핫 벡터로 인코딩을 해줍니다. 이를 원-핫 인코딩(One-Hot Encoding)이라고 부르는데요. 원-핫 인코딩은 여러 기법 중 단어를 표현하는 가장 기본적인 표현 방법이며, 단어의 크기를 벡터 차원으로 하여 표현하고 싶은 단어의 인덱스에 1의 값을 부여하고, 나머지 값은 0으로 채웁니다. (이 때 어떤 단어든 벡터상에서 벡터 거리는 루트2값을 가지며, 의미에 상관없이 모두 동일한 관계를 가지게 됩니다.) 위 예시는 10개의 고유단어를 가지므로 10차원을 가진 벡터의 크기에 맵핑되게 됩니다. 결과는 아래와 같습니다.
🧪 Vocabulary Set :
"Jadob" : [ 1, 0, 0, 0, 0, 0, 0, 0, 0, 0 ]
"loves" : [ 0, 1, 0, 0, 0, 0, 0, 0, 0, 0 ]
"studying" : [ 0, 0, 1, 0, 0, 0, 0, 0, 0, 0 ]
"Natural" : [ 0, 0, 0, 1, 0, 0, 0, 0, 0, 0 ]
"Language" : [ 0, 0, 0, 0, 1, 0, 0, 0, 0, 0 ]
"Science" : [ 0, 0, 0, 0, 0, 1, 0, 0, 0, 0 ]
"is" : [ 0, 0, 0, 0, 0, 0, 1, 0, 0, 0 ]
"difficult": [ 0, 0, 0, 0, 0, 0, 0, 1, 0, 0 ]
"to": [ 0, 0, 0, 0, 0, 0, 0, 0, 1, 0 ]
"study" : [ 0, 0, 0, 0, 0, 0, 0, 0, 0, 1 ]
Step 3. 벡터 값을 모두 더해 원-핫 벡터의 합으로 표현하기
그리고 이렇게 구한 원-핫 벡터 값을 모두 더하면 최종적으로 하나의 문장을 하나의 벡터 표현형으로 나타낼 수 있게 됩니다. (문장은 개수가 2개 이상 나타날 경우 숫자가 1보다 커질 수 있습니다.)
- 예시 문장 1: Jadob+loves+studying+Natural+Language+Processing : [1, 1, 1, 1, 1, 1, 0, 0, 0, 0]
- 예시 문장 2: Natural+Language+Processing+is+difficult+to+study : [0, 0, 0, 1, 1, 1, 1, 1, 1, 1]
이렇게, 문장 혹은 문단 등 문서를 벡터를 이용해서 표현할 수 있습니다.
코드로 실습을 해보실 분들은 scikit-learn에 있는 CountVectorizer를 이용해 실습해보실 수 있습니다. 아래의 샘플 코드를 활용해보세요.
from sklearn.feature_extraction.text import CountVectorizer
example_sentences = ["Jadob loves studying Natural Language Processing", "Natural Language Processing is difficult to study"]
one_hot_encoding = CountVectorizer()
for i, sentence in enumerate(sentences) :
print(f"BoW of sentence_{i} : {one_hot_encoding.fit_transform(sentence).toarray()})
2️⃣ Naive Bayes Classifier for Document Classification
문장 혹은 문서를 벡터의 형태로 정리해줬으니 이제 Naive Bayes Classifier를 이용해서 문서 분류를 진행해줄 수 있습니다.나이브 베이즈 분류기는 베이즈 정리(Bayes Theorem)를 이용한 지도 학습 방법 중 하나로, 모든 특징(feature)들이 서로 조건부 독립이라고 가정하여 결합 확률을 계산합니다. 즉, 단어들이 출현할 확률을 독립적이라고 가정하는 것이죠. 이후, 최종적으로 MLE(Maximum Likelihood Estimation; 최대 우도 추정)을 이용해 클래스를 분류하는 방법입니다.
문서의 수를 d, 고유 단어를 w, 클래스를 n으로 봤을 때 아래의 수식처럼 나타낼 수 있고,
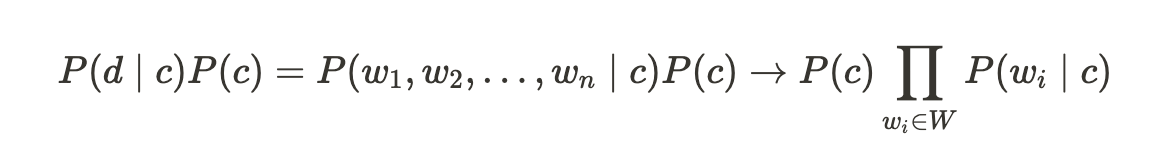
이를 통해, 문서가 등정하기 이전에 클래스가 나타날 확률과 그리고 특정 클래스가 고정돼 있을 때 각각의 워드가 나타날 확률들을 추정함으로써 Naive Bayes Classifier서 필요로 하는 파라미터를 모두 추정할 수 있게 되고, 최종적으로 문서의 클래스를 분류할 수 있게 됩니다.
단, Naive Bayes Classifier는 단어의 확률을 이용해 문서의 클래스를 추정하게 되므로, 단어가 없다면 0으로 수렴하게 됩니다. 따라서 적절한 regularization이 필요합니다.
출처 :
'NLP' 카테고리의 다른 글
| LSTM, GRU (0) | 2025.02.02 |
|---|---|
| [NLP] Recurrent Neural Network (Vanilla RNN) (0) | 2025.01.19 |
| [NLP] Backpropagation through time(BPTT)의 방법과 Long-Term Dependency 문제 (2) | 2025.01.05 |
| [NLP] Word Embedding (Word2Vec, Glove) (0) | 2024.12.22 |
| HuggingFace 모델에 RAG 적용하기(Feat. langchain) (0) | 2024.03.17 |