안녕하세요! 제이덥입니다. 오늘은 오픈소스인 HuggingFace Hub에서 LLM을 다운받아 LangChain 라이브러리를 이용해 RAG를 적용해보는 방법에 대해 포스팅합니다. RAG, HuggingFace, LangChain에 대해서 간략한 개념 설명과 함께, 실습 코드를 올려두었으니 LLM 모델의 성능 향상에 대해 고민하고 있는 분들께 도움이 되었으면 하네요.
0️⃣ RAG란 무엇인가요? 언제 사용할까요?.
LLM(Large Language Model)은 방대한 양의 언어 데이터로 학습되어, 다양한 분야에 대한 지식과 추론 능력을 갖춘 거대한 언어 모델입니다. ChatGPT, Gemini, Copilot 같은 서비스는 이러한 LLM을 기반으로 출시되어 뛰어난 성능을 보여줍니다. 그러나 도메인 특화된 영역에서는 아직 한계를 보이기도 합니다. 예를 들어, 법률 분야의 질문이나 특정 연예인에 대한 정보 요청 시 정확한 정보를 제공하지 못하거나 엉뚱한 답변을 생성하기도 합니다.
RAG는 이런 언어 모델이 특정 분야에 부족한 지식을 보충해주는 역할을 합니다. RAG는 Retrieval-Augmented Generation)의 약자로 응답을 생성하기 전에 외부의 지식 베이스를 참조하도록 하는 프로세스입니다. 즉, 학습 이외의 데이터를 생성전에 제공하여 검색
(Retrieval)하고 이를 기반으로 답변을 생성하는 것이죠.
이러한 프로세스 덕분에 LLM 모델의 할루시네이션(의도적으로 생성되는 허위 정보를 마치 '사실'처럼 말하는 현상)을 줄여줍니다. 따라서 학습 데이터 외에 도메인 관련 텍스트 데이터가 있다면 RAG를 활용해 성능을 비약적으로 향상시킬 수 있습니다.
1️⃣ HuggingFace Hub

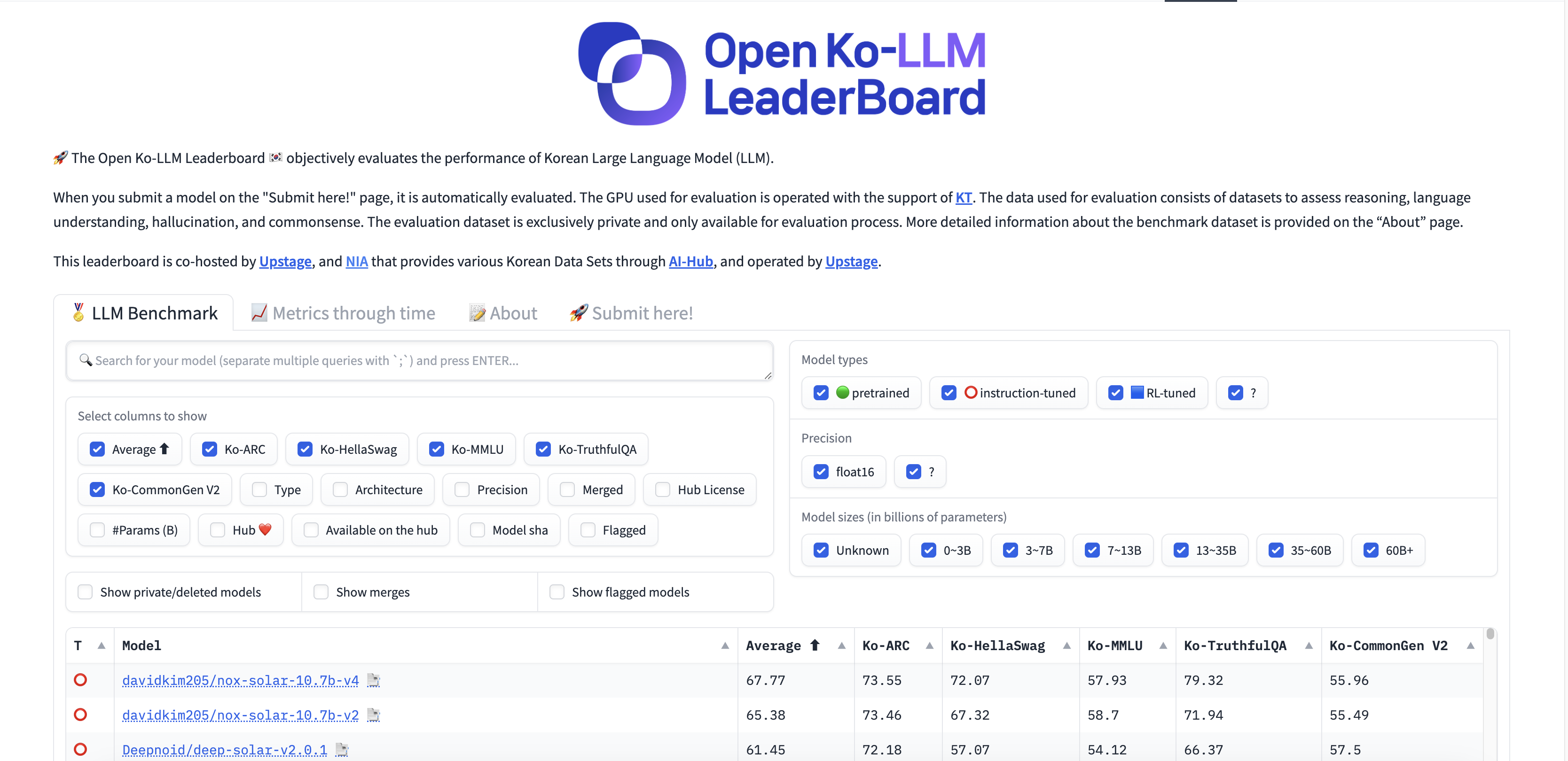
HuggingFace Hub은 미국의 인공지능 스타트업인 HuggingFace에서 만든 Git 기반의 오픈소스 플랫폼으로 35만 개의 모델, 75000개의 데이터셋을 다운받아 사용하시거나 15만개의 데모 앱(Space)을 체험할 수 있는 공간입니다. transformers 라는 PyTorch, tensorflow 기반의 파이썬 라이브러리를 이용하여 쉽게 SOTA 모델들을 다운로드 받아 fine-tuning하여 사용할 수 있기 때문에 매우 유용합니다. 오늘은 허깅페이스에서 제공하는 Open Ko LLM Leaderboard에서 모델을 찾아 다운로드 받아 RAG를 적용할 예정입니다.
2️⃣ LangChain
LangChain은 언어 모델을 이용해 애플리케이션을 개발하기 위한 프레임워크이며 prompt instruction, few shot examples 와 같은 컨텍스트 소스에 언어 모델을 연결하여 제공된 컨텍스트(정보)를 기반으로 답변을 할 수 있도록 도와줍니다.
LangChain은 프레임워크는 다음과 같은 4가지 구성으로 되어있습니다.
- LangChain 라이브러리: Python과 JavaScript 언어를 지원하며, Chain과 Agent의 다양한 구성 요소의 구현 및 조합하여 사용할 수 있는 인터페이스를 포함합니다.
- LangChain 템플릿: 다양한 작업을 위한 템플릿 입니다.
- LangServe: LangChain 체인을 REST API로 배포하기 위한 라이브러리입니다.
- LangSmith: LLM 프레임워크 위에서 구축된 체인을 디버그, 테스트, 평가, 모니터링할 수 있게 해주는 개발자 플랫폼입니다.
그리고 LangChain의 Python 라이브러리를 사용해 실습을 진행할 예정입니다.

3️⃣ 개발 환경 구성하기
LLM 모델은 높은 VRAM을 필요로 합니다. 따라서 V100, A100, RTX3090, RTX4090과 같은 높은 VRAM을 가진 GPU를 가진 로컬 환경을 준비해주세요.
제가 설치했던 라이브러리는 다음과 같습니다. (실제로는 langchain, langchain-community, faiss-gpu, sentence-transformers, pandas정도만 필요하지만, 저는 fine-tuning을 전에 진행했기 때문에 아래와 라이브러리도 추가 설치해서 사용했습니다. )
bitsandbytes==0.43.0
pandas==2.1.0
sentence-transformers==2.5.1
torch==2.2.1
torchaudio==2.2.1
torchvision==0.17.1
tqdm==4.66.2
transformers==4.38.2
langchain
langchain-community
faiss-gpu해당 파일을 requirements.txt라는 텍스트 파일에 저장해주시고, pip install -r requirements.txt를 이용해 설치해주세요.
4️⃣ RAG 파이프라인 구성하기
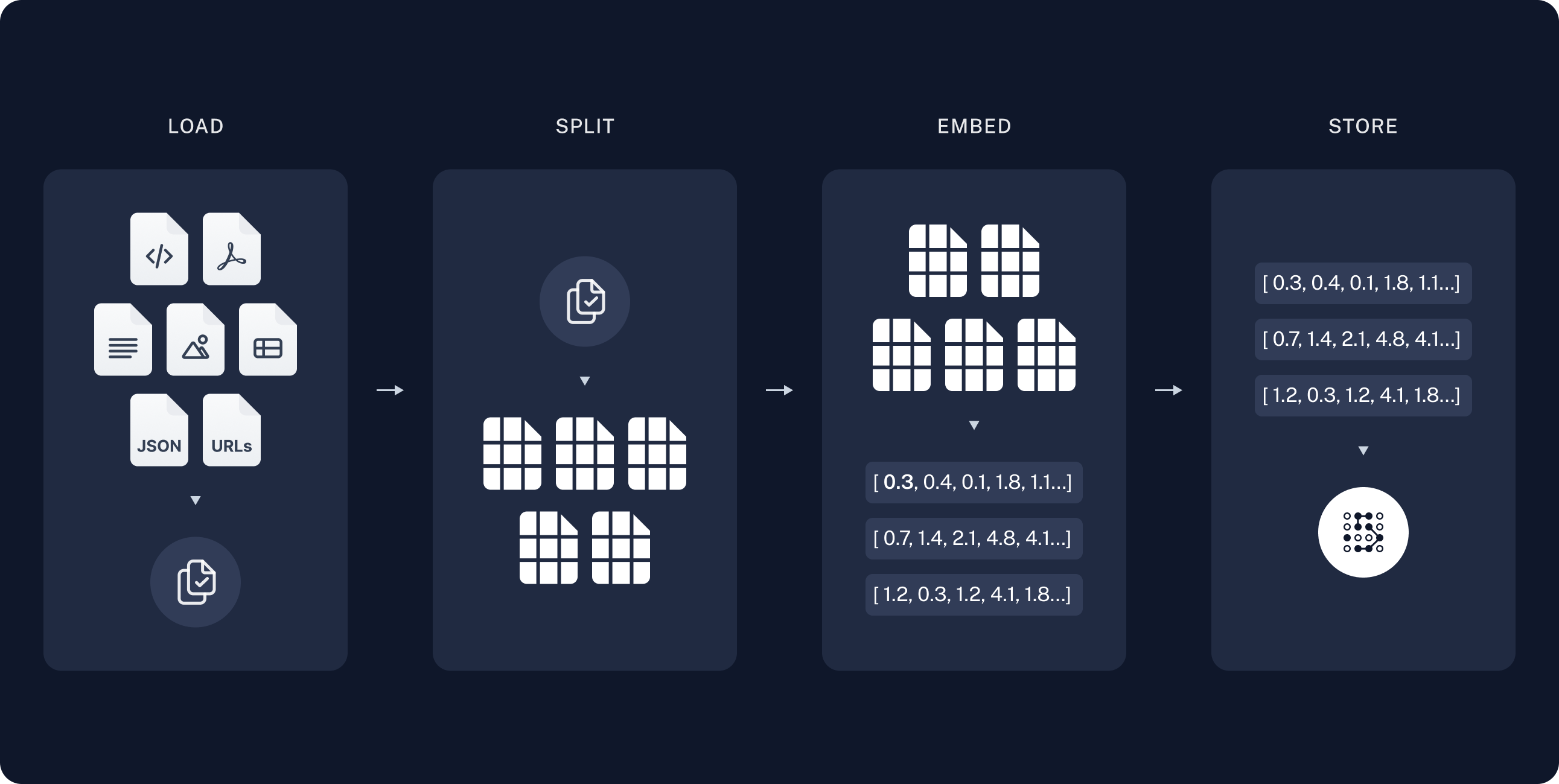
먼저 연관된 정보를 LOAD-SPLIT-EMBED-STORE 과정을 통해 저장합니다. 해당 과정은 LLM이 문서를 문단으로 나눠 벡터로 저장해주는 과정입니다. 이러한 방식으로 저장해주는 이유는 문서 검색을 하지 않기 위함인데요. 이렇게 되면 질문 내용을 벡터로 변환하여 저장된 벡터의 유사도를 통해 가장 유사한 문단을 찾아 답변을 생성해주어 정확도를 보장하는 동시에 검색으로 인한 속도의 오버헤드를 미연에 방지합니다. 이 때 주의 할 점은 문단을 나눌 때 같은 주제를 가진 문단으로 나눠줘야 한다는 것입니다. 그렇지 않으면 문단간 정보가 혼재되어 있기 때문에 성능 향상에 어려움을 겪을 수 있습니다.
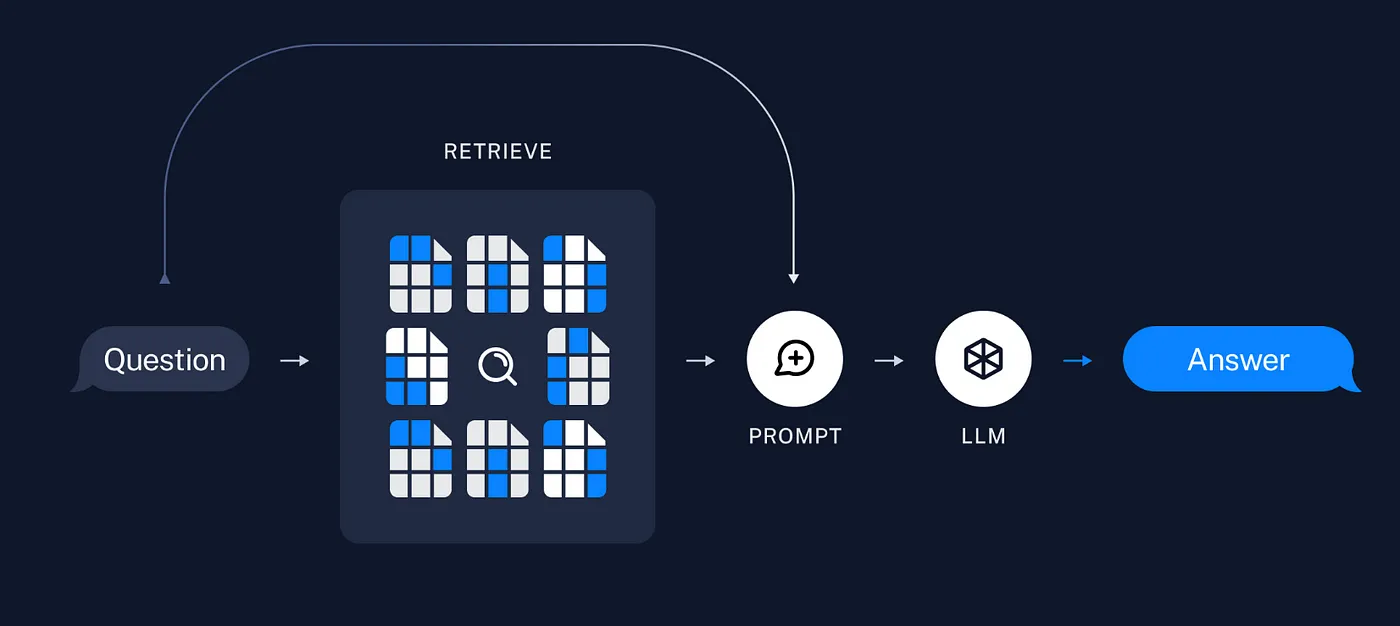
질문을 기반으로 저장된 벡터 스토어에 Retriever를 사용하여 검색을 합니다. 이후 질문, 검색 결과를 포함한 프롬프트를 이용하여 답변을 생성합니다.
이 과정을 코드에 녹여내 보겠습니다.
우선 먼저 설치했던 라이브러리에서 필요한 함수와 클래스를 import 합시다.
import pandas as pd
from itertools import product
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitterimport CharacterTextSplitter
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import FAISS
from langchain_community.llms.huggingface_pipeline import HuggingFacePipeline
from transformers import LlamaForCausalLM, AutoTokenizer, pipeline
from langchain_core.prompts import PromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
import pickle
from sentence_transformers import SentenceTransformer
from utils import set_seed
from tqdm.auto import tqdm1. RAG에 사용할 Documentation로드
우선 LLM에 제공할 외부 데이터 소스를 불러옵니다. 데이터는 웹에서 크롤링 하여 가져올 수도 있고, PDF, text, CSV 데이터가 될수도 있습니다. 이번 실습에서는 PDF파일을 가져와 읽어보겠습니다.
# LangChain을 통한 파일 로드
# PyPDFLoader에 경로 저장
loader = PyPDFLoader("PDF저장된_경로/PDF파일이름.pdf")
# load()함수를 통해 페이지 별 문서 load
docs = loader.load()2. SPLIT
text_spliter를 정의해 쪼개줍니다. 문단 사이즈(chunk_size), separater 등 다양한 옵션을 줄 수 있습니다.
text_splitter= CharacterTextSplitter(
separator="\n\n",
chunk_size=100,
chunk_overlap=10,
length_function=len,
is_separator_regex=False,
)
splits = text_splitter.split_documents(docs)3. EMBED & STORE
저는 해당 데이터가 한국어로 되어 있기 때문에 distiluse-base-multilingual-cased-v1 라는 모델의 임베딩 벡터를 이용해 데이터를 저장해주었습니다.
modelPath = "distiluse-base-multilingual-cased-v1"
model_kwargs = {'device':'cuda'}
encode_kwargs = {'normalize_embeddings': False}
embeddings = HuggingFaceEmbeddings(
model_name=modelPath,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs
)
# 임베딩 생성
db = FAISS.from_documents(data, embedding=embeddings)
# 임베딩 저장
db.save_local("Embedding Store")4. 검색 및 생성
# 검색한 문단을 하나의 문서로 합쳐줍니다.
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# Embedding Store에서 검색할 준비
retriever = vectorstore.as_retriever()
# HuggingFace에서 모델 다운로드(fine-tuning된 모델이 있다면 모델 저장공간을 불러오셔도 됩니다.)
model_id = "davidkim205/nox-solar-10.7b-v4"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
config.base_model_name_or_path,
device_map={"": 0},
torch_dtype=torch.float16,
)
# 파이프라인 구성
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer, max_new_tokens=256)
llm = HuggingFacePipeline(pipeline=pipe)
# RAG 템플릿 구성
# context : 정보 , qeustion: 사용자 질문
template = """마지막에 질문에 답하려면 다음과 같은 맥락을 사용합니다.
{context}
질문: {question}
유용한 답변:"""
custom_rag_prompt = PromptTemplate.from_template(template)
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| custom_rag_prompt
| llm
| StrOutputParser()
)5. 답변 생성
question = "논문에서 정의한 RAG는 무엇인가요?"
response = rag_chain.invoke(question)
print(response)RAG, HuggingFace Hub, LangChain에 대한 간략한 설명과 실습 노트를 구성해봤습니다. 궁금한 점이 있다면 댓글로 남겨주세요. 참고 자료는 아래 링크에서 확인할 수 있습니다.
Reference :
'NLP' 카테고리의 다른 글
| [NLP] Recurrent Neural Network (Vanilla RNN) (0) | 2025.01.19 |
|---|---|
| [NLP] Backpropagation through time(BPTT)의 방법과 Long-Term Dependency 문제 (2) | 2025.01.05 |
| [NLP] Word Embedding (Word2Vec, Glove) (0) | 2024.12.22 |
| [NLP] Bags of Words & Naive Bayes Classifier for Document Classification (2) | 2024.11.10 |