안녕하세요! 제이덥입니다. 최근에 기술 면접을 준비하며, 기초적인 내용부터 하나씩 정리하고 있는데요. 오늘은 RNN이란 무엇이며 어떤 문제를 해결할 수 있는지, 어떻게 작동하는지에 대해서 종합적으로 정리하여 포스팅합니다.
1️⃣ RNN(Recurrent Neural Network)의 탄생 배경
탄생 배경: 피드 포워드 신경망(FFNN)은 입력의 길이가 고정되어 자연어와 같이 입력이 가변적인 길이를 가진 시퀀스 데이터를 처리하는데 한계가 있었습니다. 이러한 한계를 극복하기 위해, 다양한 입출력 길이를 다룰 수 있는 인공신경망이 필요하게 되었고 여러 연구가 진행되었습니다. 그 결과 '순환 신경망이라고 불리는 Recurrent Neural Network(이하 RNN)이 등장했습니다.
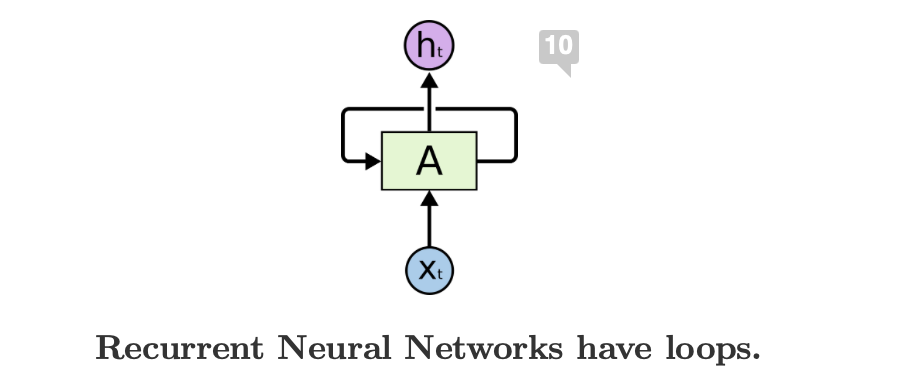
2️⃣ RNN의 작동원리
RNN 정의: RNN은 입력과 출력을 시시퀀스 단위로 처리하는 대표적인 시퀀스 모델 중 하나입니다. 따라서 순서를 가진 데이터인 자연어, 비디오, 음성, 시계열 데이터를 처리할 수 있습니다. 기존 피드포워드 신경망과 달리, RNN은 현재 시점(t)의 입력뿐만 아니라, 이전 타임스텝에서 계산된 히든 스테이트(hidden state)를 활용하여 최종 출력을 결정합니다.
기본 구조: RNN은 위와 같이 압축된(Rolled Up) 구조나 아래와 같이 펼쳐진(Unrolled) 구조 형태로 나타낼 수 있습니다. 모든 타임스탬프를 계산할 때마다 동일한 가중치를 사용하며, 입력 벡터(t)와 전 타임의 히든 벡터(t-1)를 입력받아 출력을 계산합니다. (이렇게 동일한 파라미터를 재귀적으로 호출하여 계산하는 특성때문에 RNN(Recurrent Neural Network)라는 이름을 가지게 되었습니다.)

계산 방법: 계산에 필요한 변수들은 아래와 같습니다. 바로 이전 타임스텝의 히든 벡터와, 현재 타임스텝의 입력벡터 그리고 이를 연산할 파라미터 W입니다. 그리고 이 값들에 행렬 곱을하고 비선형 함수인 tanh를 함수를 적용해 현재 타임 스텝의 히든 벡터와 최종 출력을 계산합니다.이때, 최종 출력층을 제외한 히든 벡터의 활성 함수로 주로 tanh 함수가 사용되며, 이는 기울기 소실 문제를 어느 정도 완화할 수 있기 때문입니다.
- t : 현재 타임스텝(time step) , w : 웨이트(weight)
- h_(t-1) : old hidden-state vector
- x_t : input vector at some time step
- h_t : new hidden-state vector
- f_w : RNN function with parameters W
- y_t : output vector at time step t
2️⃣ RNN의 활용 방법과 한계
활용방안: RNN은 입출력을 자유롭게 조절할 수 있기 때문에 다양한 형태의 Task를 처리할 수 있습니다. one-to-one, one-to-many, many-to-one, many-to-many 형태의 Task를 처리할 수 있는데요. 정리하면 아래와 같습니다.
- one-to-one : 대표적인 RNN 형태. 분류 ( 키/몸무게/나이 같은 정보를 입력, 저혈압/고혈압인지 분류하는 형태의 태스크)
- one-to-many : '이미지 캡셔닝' (하나의 이미지를 입력, 설명글을 출력으로 생성하는 태스크)
- many-to-one : 감성 분석( 긍/부정 중 하나의 레이블로 분류하는 태스크)
- many-to-many : 기계 번역(입력을 끝까지 다 읽은 후 번역된 문장을 출력해주는 태스크)
- many-to-many : 비디오 분류 (영상의 프레임 레벨에서 예측하는 태스크), POS (각 단어의 품사에 대해 태깅하는 태스크)

한계: 다만, RNN은 이러한 장점에도 불구하고 Gradient Vanishing/Exploding 문제에서 자유롭지 않습니다. 이를 해결하기 위해 Truncated BPTT를 적용하였지만, 시간 순서상 멀리 떨어져 있는 데이터의 정보를 유지하는데 큰 어려움을 겪고 있습니다. 이러한 문제를 해결하기 위해 LSTM, GRU, Transformer등이 고안되었습니다.
'NLP' 카테고리의 다른 글
| [NLP] Backpropagation through time(BPTT)의 방법과 Long-Term Dependency 문제 (2) | 2025.01.05 |
|---|---|
| [NLP] Word Embedding (Word2Vec, Glove) (0) | 2024.12.22 |
| [NLP] Bags of Words & Naive Bayes Classifier for Document Classification (2) | 2024.11.10 |
| HuggingFace 모델에 RAG 적용하기(Feat. langchain) (0) | 2024.03.17 |