안녕하세요, 제이덥입니다! 기술 면접을 준비하면서 기초 개념들을 하나씩 정리해보고 있는데요. 오늘은 Sequence to Sequence 모델과 Encoder-Decoder 구조를 시작으로, “Attention is All You Need” 이전의 Attention 메커니즘을 알아보고, 마지막으로 이를 활용한 Seq2Seq 모델까지 함께 정리해보려고 합니다.
1️⃣ Sequence to Sequence Model
초기 Sequence to Sequence 모델(이하 Seq2Seq 모델)은 NMT(Neural Machine Translation)와 같은 문장 번역이나 문장 생성과 같은 Many-to-Many 태스크를 해결하기 위해 활용되었습니다. 이는 입력과 출력을 모두 시퀀스 형태로 처리하는 데 특화되어 있기 때문입니다.
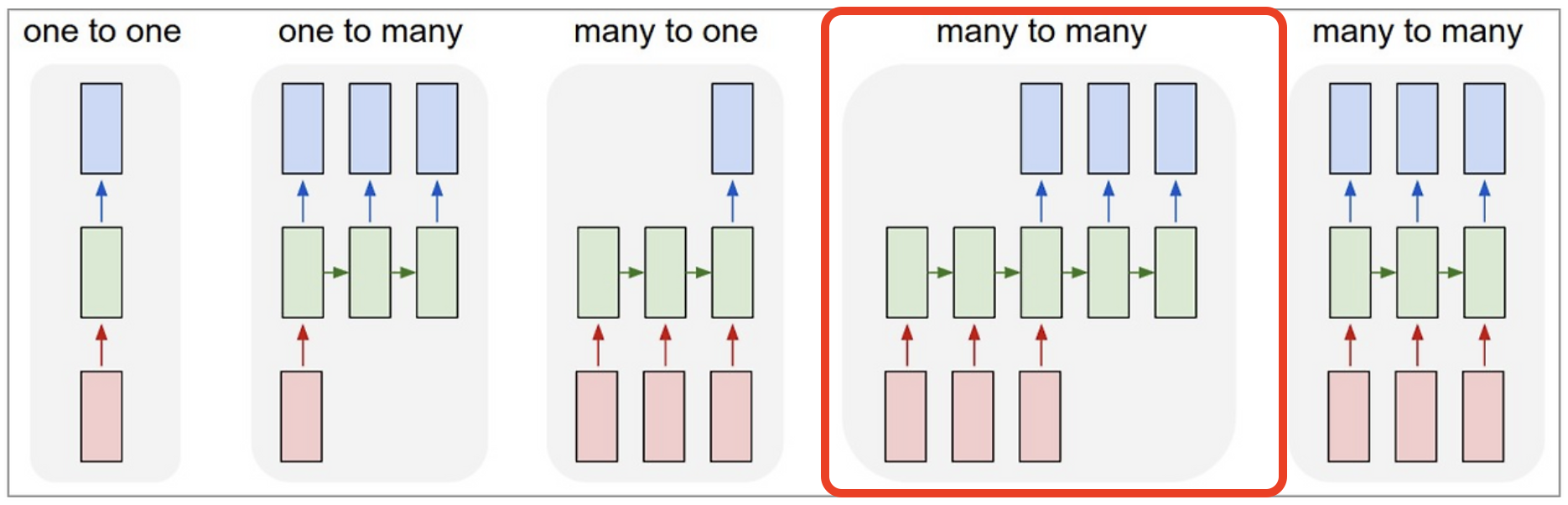
초기 Seq2Seq 모델은 RNN, LSTM과 같은 순환 신경망을 기반으로 한 Encoder-Decoder 구조로 이루어져 있습니다. 이 모델은 입력 문장을 처리하는 RNN 계열의 Encoder와, 이를 기반으로 출력을 생성하는 RNN 계열의 Decoder로 구성된 것이 특징입니다. Encoder는 입력 문장을 읽어 hidden vector에 문장의 정보를 압축적으로 저장하며, 이 hidden vector는 context vector로 전달되어 Decoder의 입력으로 활용됩니다. 이를 통해 Decoder는 최종적으로 문장을 출력할 수 있게 됩니다.
또한, Seq2Seq 모델은 문장의 시작을 알리는 SoS(Start of Sentence) 토큰과 문장의 끝을 알리는 EoS(End of Sentence) 토큰과 같은 특수 토큰들을 정의합니다. 이를 통해 모델이 첫 번째 단어부터 문장을 생성하고, 마지막에 문장 생성을 종료할 수 있도록 구현됩니다.

다만, 이러한 구조에는 여전히 한계가 존재합니다. 바로 마지막 시점의 hidden state만 전달되기 때문에, 이전 단어들의 정보가 손실될 가능성이 있다는 점입니다. 예를 들어, Step 1, 2, 3, 4 순서로 “I, am, a, student”라는 입력이 주어진 경우를 생각해보면, 번역되어 생성된 문장에서 주어가 Step 1의 ‘I’여야 합니다. 하지만 Step 4 시점의 hidden state만 전달되다 보니, 이전 단어들에 대한 정보가 충분히 반영되지 못하고 손실됩니다. 이러한 문제는 특히 긴 문장을 처리할 때 더욱 두드러지게 나타납니다.
2️⃣ Seq2Seq Model with Attention: Attention Mechanism
이를 해결하기 위해 기존에는 입력 문장을 거꾸로 집어넣는 방식이 사용되기도 했지만, Attention Mechanism이라는 더 효과적인 방법이 등장했습니다. Attention Mechanism의 핵심 아이디어는 간단합니다. 각 타임스텝(time step)에 저장된 정보를 보존하면서, 필요할 때 이를 선별적으로 활용하는 것입니다. 특히, 출력 결과를 생성할 때 인코더(Encoder)의 어떤 타임스텝에 더 집중해야 하는지를 모델이 학습하도록 구현하는 것이 핵심입니다.
이제 Seq2Seq 모델에 Attention을 적용한 구조를 살펴보겠습니다. 예를 들어, 4개의 단어로 구성된 문장이 입력으로 주어졌다고 가정해봅시다. 이 경우 총 4번의 타임스텝이 생성되며, 각 타임스텝에서 hidden state가 계산됩니다. Attention Mechanism에서는 기존 인코더-디코더 구조와 달리, 각 타임스텝에서 디코더 RNN의 hidden state와 인코더의 hidden state 간에 내적을 계산합니다. 이를 통해 4개의 타임스텝에 대한 Attention Score가 생성되며, 이 스코어는 Softmax를 거쳐 합이 1인 형태의 Attention Vector로 변환됩니다.
이 Attention Vector는 디코더 RNN과 결합되어 최종적으로 하나의 단어를 출력하게 됩니다. 이러한 방법을 통해 이전 시점의 단어 손실을 최소화할 뿐만 아니라, 모델이 출력 시 더 집중해야 할 단어를 효과적으로 학습할 수 있게 됩니다.

3️⃣ Seq2Seq Model with Attention 학습 방법 : Teacher Forcing
Seq2Seq 모델의 디코더 hidden state는 최종적으로 output layer의 입력으로 사용되며, 어떤 단어 벡터(Vector)를 선택할지 결정하는 역할을 합니다. 따라서 학습 과정에서는 두 가지를 학습해야 합니다. 첫째, 단어를 추출하는 부분과, 둘째, 정보를 선택하는 부분입니다. 이 두 가지는 모두 Backpropagation을 통해 학습되며, Attention을 계산하는 방향과 Decoder의 단어 추출 방향으로 각각 이루어집니다.
또한, Sequence 데이터의 특성상 학습 중 첫 번째 timestep에서 잘못된 예측을 할 경우, 이 단어가 이후 timestep의 입력으로 활용되기 때문에 학습이 원활하지 않을 가능성이 큽니다. 이를 방지하기 위해 훈련 과정에서는 Ground Truth를 입력으로 사용하는 Teacher Forcing 방법이 활용됩니다. 이 방법은 모델이 잘못된 학습에 빠지는 것을 방지하지만, 학습 환경과 실제 테스트 환경 간의 괴리가 생긴다는 단점이 있습니다. 따라서 초기 학습 단계에서는 Teacher Forcing을 이용해 학습을 진행하다가, 성능이 일정 수준 이상으로 개선되면 Teacher Forcing을 사용하지 않고, 이전 timestep에서 예측된 값을 입력으로 넣어 학습을 진행합니다.
4️⃣ 다양한 Attention Mechanism과 효과
이후, 이러한 Luong, Bahdanau 등이 Attention Mechanism을 발전시켰습니다. 아래의 식을 예시를 들면
- Luong - dot : 간단한 내적을 통한 유사도(어텐션) 측정하는 기법으로, 학습가능한 파라미터가 존재하지는 않습니다.
- Luong - general : 유사도를 구하고자하는 두 벡터 사이에, 학습가능한 파라미터로 구성된 행렬을 활용합니다.
- Luong - concat : 유사도를 구하고자하는 두 벡터를 concat하여 선형변환(비선형성(선형변환(x)))으로 감싸서 계산을 진행합니다.

그리고 이러한 Attention Mechanism은 아래와 같은 효과를 갖습니다.
- NMT Task 성능 향상
- 긴 문장 번역 어려움 해결
- 기울기 소실 문제 완화
- 해석성 제공
출처 :
- 부스트코스 강의 : 자연어 처리의 모든 것 - Seq2Seq Model
- 부스트코스 강의 : 자연어 처리의 모든 것 - Seq2Seq Model with Attention Mechanism
- 부스트코스 강의 : 자연어 처리의 모든 것 - Attention Mechanisms
- [NLP 논문 리뷰] Sequence To Sequence Learning With Neural Networks (Seq2Seq)
- 2017 CS231n - Lecture 10: Recurrent Neural Networks
'NLP' 카테고리의 다른 글
| BLEU Score (1) | 2025.03.16 |
|---|---|
| Greedy Decoding vs. Beam Search vs. Exhaustive Search: 텍스트 생성 알고리즘 비교 (0) | 2025.03.02 |
| LSTM, GRU (0) | 2025.02.02 |
| [NLP] Recurrent Neural Network (Vanilla RNN) (0) | 2025.01.19 |
| [NLP] Backpropagation through time(BPTT)의 방법과 Long-Term Dependency 문제 (2) | 2025.01.05 |