안녕하세요~
패스트캠퍼스 교육생 제이덥입니다!
오늘은 "머신러닝 개요" 1주차 강의를 듣고
깨달았던 부분 더 공부해야 할 부분들을 포스팅을 통해 점검 해볼까 합니다.
.
.
"먼저 포스팅 관련 내용은
[KDC] 패스트캠퍼스 머신러닝& AI 첫걸음 시작하기 강의를 토대로 작성되었음을 알려드리며,
자세한 공부 하기를 원하시는 분들은 패스트캠퍼스강의를 수강하시기 바랍니다!"
.
.
.
머신러닝 AI 1주차는
Part 1
머신러닝이 무엇인지, 어떻게 학습을 하고 검증을 하는지 또한 고려해야하는 대상은 무엇인지,
Part 2
머신러닝에 필요한 통계학적 지식, 수학적 지식
크게 두 부분으로 나누어 강의를 진행되었습니다.
사실 학교에서
데이터 마이닝, 통계, 딥러닝에 대해서 수강한 강의도 있었고, 수강을 하고 있는 강의도 있었습니다.
그리고 강의 이름이 "머신러닝& AI 첫 걸음 시작하기"인 만큼
이미 내용에 대해 어느정도 숙지하고 있어 새롭다는 느낌은 못 받았을 것 같았는데,
강의가 신선하고 세련됬다는 느낌을 받았습니다.

강의가 새롭다는 느낌을 받았다는 것은 다음과 같은 이유 때문이었던 것 같습니다.
대부분 제가 들었던 강의는 이론적인 내용에 많은 중심을 두는 강의였습니다.
제가 들었던 대부분의 강의는 이론적인 부분을 논증을 통해 접근하며,
코드에 적용하는 예시를 통해 이론적인 부분을 매우 상세하게 설명했었습니다.
적용되는 사례에 대해 설명이 부족함을 느껴
내용이 매우 어렵게 느껴졌으며, 이해하기 위해 몇번이고 돌려보거나
다른 내용을 많이 찾아와야 되었던 것 기억이 있네요.
그런데 이 과정에서는 정의를 매우 정확하고 깔끔하게 내려주시고,
간단하고 이해가 쉬운 보충 설명, 그리고 쉬운 단어들로 설명을 해주셨습니다.
또한 적절한 예시를 들어주셨고, 예시가 이해가 될 수있도록 상세하게 설명을 해주셨습니다.
Part1
예를 들면 머신러닝 개요(1)에서
모델의 검증 방법을 설명할 때가 있었습니다.
제가 들었던 그 전 대부분의 강의에서는 아래와 같은 그림을 통해서
Overfitting은 분산이 높은 경우, 편차가 낮은경우
Underfitting은 분산이 낮고, 편차가 높은 경우라고 설명을 해주었던 것 같습니다.
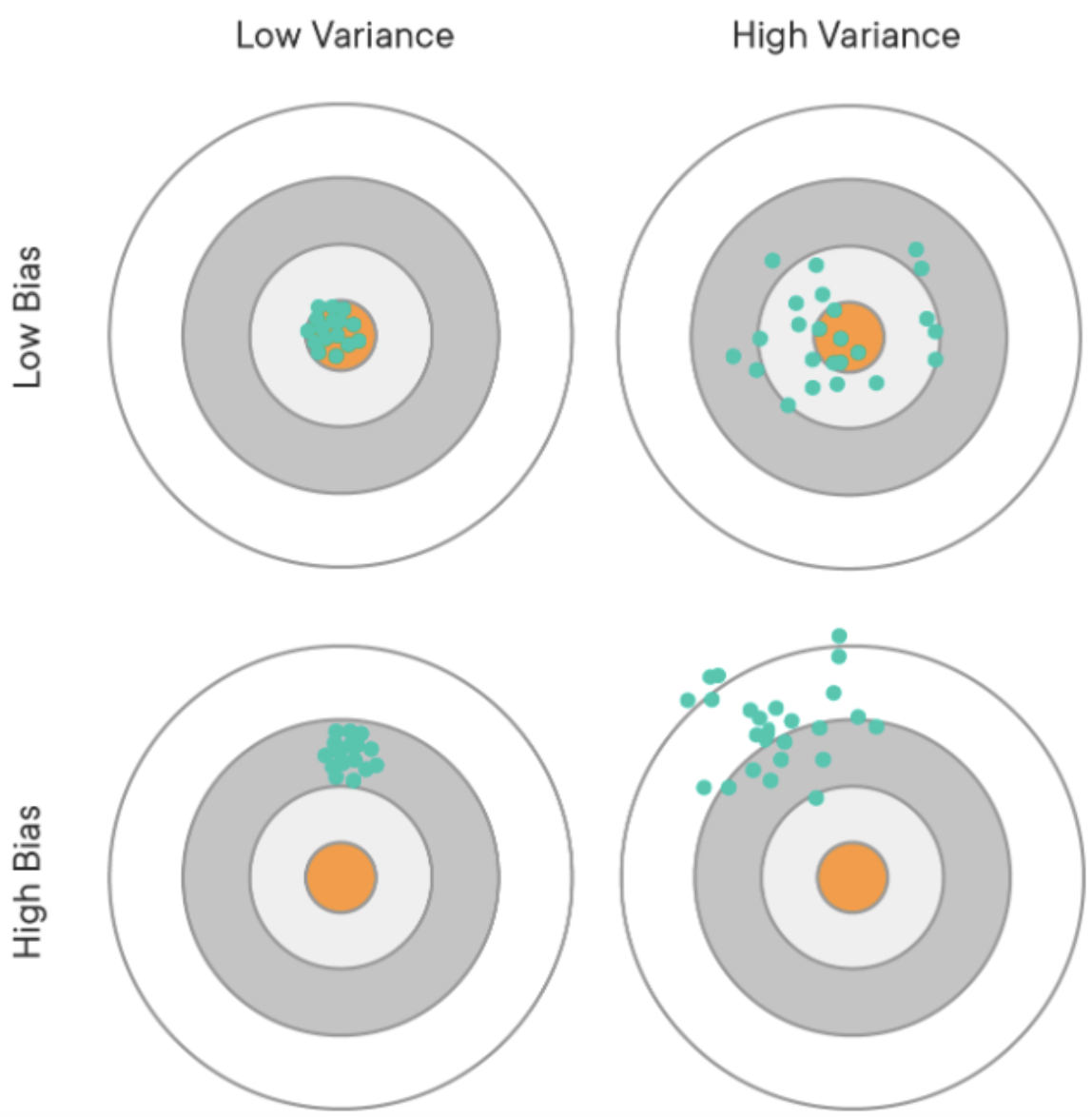
그러나 이번 강의에서는 여러가지 함수그래프를 통해서
직접 분산과 편차가 달라지는 경우를 설명해주었고,
수식적으로 식으로도 접근해서 문제에 대해서 설명을 해주셨으며,
그리고 위와 같은 그림을 이용해주어서 설명을 해주었습니다.
따라서 직관적으로, 수식적으로, 그래프적으로 설명을 해주었기 때문에
보다 확실하게 이해를 할 수 있었던 것 같습니다.
또한 대부분의 강의는 train set, validation set, test set을 나누는 이유에 대해서
단순히 위와 같은 과적합이 일어나기 때문이라고 이야기하고 넘어갔었습니다.
그리고 이러한 방법이 전형적인 방법이라고 설명하고 넘어갔었습니다.
따라서,
저는 이 강의를 듣기 전까지는 대부분의 모델링을 할 경우
이러한 방법으로 학습&검증 방법을 진행해야 된다고 생각했었습니다.
그러나 이번 강의에서는
train set, validation set, test set으로 나눠야 하는 이유를 설명하는
동시에 언제 이 방법이 효과적인지
( 여기서는 Hyperparameter가 주어지지 않은 경우라고 말해주었습니다)
또 만약 parameter를 튜닝할 필요가 없는 경우에는
train set과 test set으로 나눠도 가능하다는 점,
학습에 필요한 데이터가 존재할 경우 k-fold cross validation을 권한다는 점,
또 데이터가 적을 경우에는 LOOCV(Leave One Out Cross Validation )을 권한다는 것 ,
그리고 데이터의 전처리부터 학습 설계, 검증까지 이루는 과정을
주식이나 쉬운 예시를 들어서 설명해주셔서
어떤 케이스에 어떤 방식을 적용해야 되며 예외는 어떤것인지에 대해서 배울 수 있었던 것 같습니다.
또 앙상블 모델과 같은 개념적으로 확실하게 정의 하지 못했던 것들도 이 강의에서 학습할 수 있어서 좋았습니다.
이 외에도 머신러닝의 기분개념(분류와 패턴추출), 지도학습과 비지도학습,
그리고 비지도학습의 중요성, 알파고를 탄생시킨 강화학습에 대해
그리고 다양한 머신러닝에 방법 K-nn, SVM, 회귀분석, 의사결정 나무 등
다양한 머신러닝의 개념에 대해서 학습하였습니다.
Part 2
Part 2에서는 수학적인 부분에 대해서 다뤘습니다.
특히 이 부분은 두 부분으로 나누어져 있었는데,
처음에는 통계와 관련된 내용
실험적 통계, 확률, 평균 등 기초적인 내용을 전반적으로 다뤄줬고,
이후에는 도함수와 likelihood, MLE, Matrix에 대해서 배웠습니다.
간략하게 이전에 학습했던 통계와 미분과 같은 개념들을 다시 한번 정리할 수 있었던 것 같습니다.
1주차를 배우며 개념적인 부분을 많이 배웠습니다.
최대한 필요 없는 내용을 많이 걸러내시고 강의를 하셨던 것 같기에
대부분의 내용을 잘 숙지하고 있어야 할 것 같다는 느낌이 들었네요.
내용이 많은 만큼 복습하면서 정리를 해봐야겠네요~
2주차로 돌아오겠습니다!
출처 :
1) 패스트 캠퍼스 : https://fastcampus.co.kr
패스트캠퍼스 [직장인 실무교육]
프로그래밍, 영상편집, UX/UI, 마케팅, 데이터 분석, 엑셀강의, The RED, 국비지원, 기업교육, 서비스 제공.
fastcampus.co.kr
2) 강사님 :
이경택 강사님 - 머신러닝&AI 첫 걸음 시작하기 1주차 Part 1
김강진 강사님 - 머신러닝&AI 첫 걸음 시작하기 1주차 Part 2-1 & 1주차 Part2-2