안녕하세요~
패스트캠퍼스 교육생 제이덥입니다!
오늘은 "머신러닝 개요" 4주 차 강의를 듣고
배웠던 부분과 더 공부해야 할 부분들을 포스팅을 통해 점검해볼까 합니다.
.
.
"먼저 포스팅 관련 내용은
[KDC] 패스트캠퍼스 머신러닝& AI 첫걸음 시작하기 강의를 토대로 작성되었음을 알려드리며,
자세한 공부 하기를 원하시는 분들은 패스트캠퍼스 강의를 수강하시기 바랍니다!"
.
.
.
오늘 배웠던 핵심적인 내용은
"앙상블 모델"이었습니다.
앙상블은 영어로 "Ensemble"이라고 하는데
전체적인 조화를 뜻합니다.
이 앙상블 모델은 어떤 모델인지 감이 오시나요?
바로 모델 여러개를 합하여 하나의 모델을 만드는 것을 바로
앙상블 모델이라고 말합니다.
.
.
.
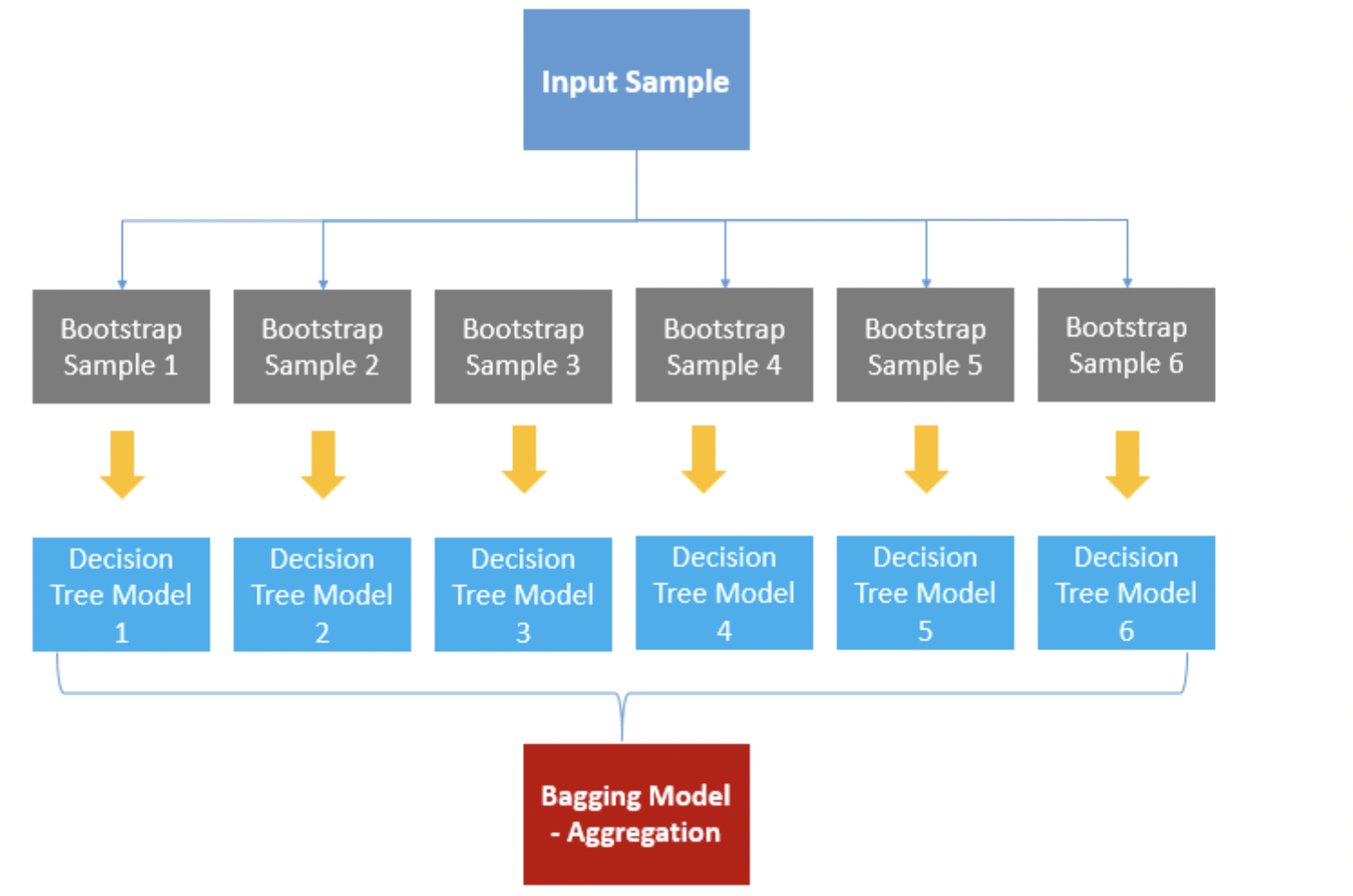
이 앙상블 모델을 만들수있는 모델은 크게 3+1구조로 되어있는데요.
데이터에 변화를 주어 다른모델을 만들어내는 Bagging
데이터, 변수 둘다 변화를 주어 모델을 다양하게 해주는 RandomForest
맞추기 어려운 데이터에 가중치를 더해 모델을 만든 Boosting
모델의 ouput값과 fold를 이용해서 새로운 데이터를 만들어내어 학습하는 Stacking에대해서 배웠습니다!
이 모델들 뿐만아니라 앙상블의 앙상블, 변수추출 기법, Sharp Value에 대해서도 배웠습니다.
오늘도 간략하게 설명하고 넘어가도록 하겠습니다..!!
총총
.
.
우선 앞서 말씀드렸던것처럼 앙상블 모델은 다양한 모델을 이용해서 만들어집니다.
Knn, Tree와 같은 모델들을 Weak Leaner들을 모아
평균을 내거나 최적의 방법을 투표를 통해 Stronger Learner를 만드는 작업입니다.
이러한 방식이 가능한 이유는 "대수의 법칙"이라는 통계적인 법칙과
여러가지 시선은 결국 가장 좋은 시선을 만들어 낼 수 있다는 관점에서 시작합니다.
Bagging은
Decision Tree나 Regression과 같은 학습을 하게 되면
같은 데이터를 주게 되면 항상 같은 데이터가 나오게 됩니다.
따라서 이런 모델들을 Learner로 이용하기 위해서는
데이터 값을 임의로 다르게 해서 학습을 해줄 수 있는데요.
비복원 추출을 통해 데이터의 값을 변화 시켜 학습을 하여
다양한 모델을 만들어 내는 학습입니다.
RandomForest은
Bagging에서 한가지를 추가합니다.
Bagging에서 독립이라는 조건이 있는데, 사실상 같은 데이터를 비복원 추출하기 때문에
공분산이 0이 되지 않습니다.
따라서 변수를 선택적으로 사용함으로서 이런 독립을 보장하게 하는 것인데요.
이 방법은 Tree구조 또한 Overfitting이 잘되는 모델을 이용하면 매우 효과적이라고 합니다.
Boosting은
맞추지 못한 데이터에 가중치를 두는 방식으로
다음 데이터를 선택하는 방식입니다.
가장 기본적으로 이용하는 AdaBoost방식과
가장 트렌디하게 이용할 수 있는 Gradient Boosting에 대해서 배워봤습니다.
Gradient Boosting은 학습된 잔차를 계속해서 예측하여 최종 error를 0으로 만드는 기법인데요
크게 세가지 XGBoost, LightGBM, CatBoost 방법으로 나뉘는 데요.
이 방식은 Gradient Boosting에 Regularization이나 특성을 추가하여 보다 나은 모델로 만들어준 방법입니다.
마지막으로 Stacking입니다!
이 방식은 train데이터를 여러 fold로 나누고 output데이터와 결합하여 하는 학습 방식인데요.
성능을 높여줄 수 있으나, 효율이 낮아
대회가 아니면 현업에서 잘 사용되지 않는다고 합니다..!
이상 간단한 이론 설명이었구요!
이번 강의에서는 특히나 실습이 많아 배웠던 내용을 바로바로 실습해보며
원리를 적용해보는 시간이 충분히 확보되었던게 장점이었던 수업이었습니다.
그 전에 앙상블 모델이 그 전에 공부할 때는 단순히 의사결정회귀나무에서만 해봤어서
깊게 공부할 기회가 없었는데 이번 시간을 통해서 여러가지 기법에서 살펴 볼 수 있었던 좋은 기회였습니다.
매번 느끼는 것이지만 비슷한 데이터를
다양한 모델에 적용해보며 어떻게 결과가 변화하는지 체크하는 부분이 상당히 공부를 하는데 많이 도움이 되는 것 같습니다.
이번 실습에서는 하면서 Boosting이다 Bagging같은 방법으로 실습을 했을때
Mean Squared Error값이 매번 달라지는 것을 확인했었는데, 이유에 대한 설명과
반드시 이론적인 부분이 일치하지 않는것
(Bagging이나 Boosting을 진행했을 때 반드시 Mean Squared Error가 낮아지지 않았던것)을 체크하며
이론적인 부분을 실제 적용하기 위해서는 이론 뿐만아니라
많은 실습에 대한 경험도 있어야한다는 것을 알아야 하는 시간이었던 것 같네요.
.

.
.
아래 제가 실습했던 사진을 첨부합니다...!
(이번에도 과정이 유출 될 수 있어서 Output의 일부와 코드 일부만 캡처해서 올립니다!)

그리고 또한 Gradient Boosting 실습을 할 때
XGboost, Catboost, LightGBM 을 설치를 pip를 이용해서 설치를 하는 방법을 알려주었습니다.
그런데 강사님과 OS가 다르고, 프로세서가 M1 Chip이라서 그런지 pip를 이용해서 설치를 해줬을 때
경로를 설정하라는 오류가 나왔었습니다. 문제를 해결하기 위해 brew, conda 등을 이요해서 설치를 시도해 보았고,
brew 또한 문제를 해결 할 수 없었으나, 'conda install'를 통해서는 문제를 해결하여 설치를 해줄 수 있었습니다.
이후에는 오류없이 무난하게 Gradient Boosting 실습을 진행할 수 있었습니다.
pip는 Anaconda를 사용하는 m1 mac체제에 호환이 안되는 것을 알수 있었습니다.
혹시나 여러분들 중 m1 macOS Anaconda개발환경에서 boosting을 설치 때
오류가 생긴다면 'conda install'을 이용해서 문제를 해결 해보는 것을 추천해보며 이번 포스팅을 마칠게요!
오늘 하루도 좋은 하루 되세요!



출처 :
1) 패스트 캠퍼스 : https://fastcampus.co.kr
패스트캠퍼스 [직장인 실무교육]
프로그래밍, 영상편집, UX/UI, 마케팅, 데이터 분석, 엑셀강의, The RED, 국비지원, 기업교육, 서비스 제공.
fastcampus.co.kr
2) 강사님 : 이경택 강사님