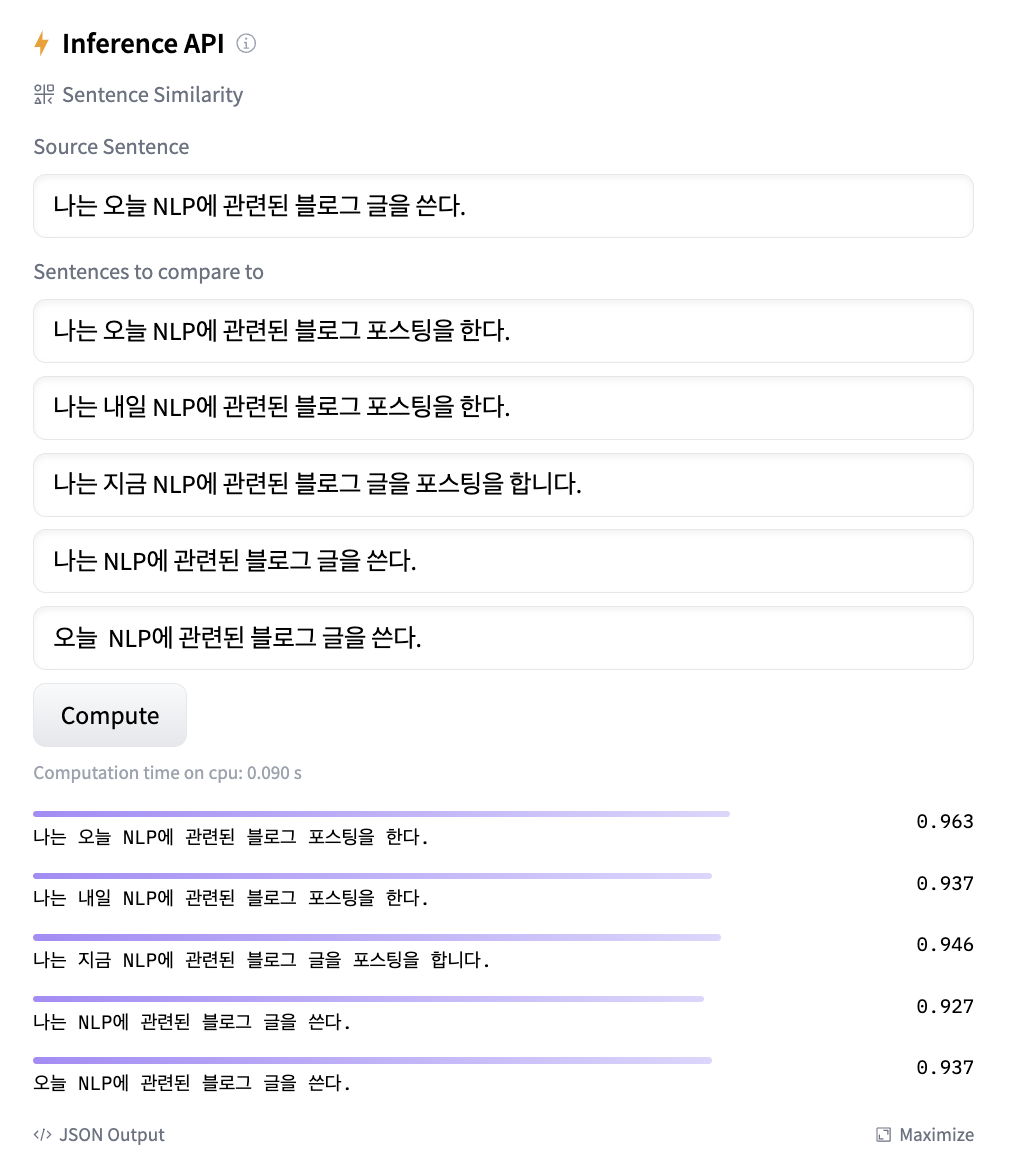
안녕하세요! 제이덥입니다. 최근에는 Dacon 대회에 참여하여 특정 도메인에 적합한 LLM(Large Language Model)을 구축하는 Task를 진행했습니다. 이 과정에서 구축한 모델의 평가지표로 코사인 유사도(Cosine Similarity)를 사용했습니다. 코사인 유사도의 기본 개념은 이해하고 있었지만, 언어모델을 평가할 때 구체적으로 어떤 의미를 가지는지 명확히 알지 못했습니다. 따라서, 코사인 유사도가 무엇인지, 언어모델을 평가할 때의 장점 및 한계점은 어떻게 되는지 이번 포스팅을 통해 정리해보고자 합니다. 1️⃣ 코사인 유사도란 코사인 유사도(― 類似度, 영어: cosine similarity)는 내적공간의 두 벡터간 각도의 코사인값을 이용하여 측정된 벡터간의 유사한 정도를 의미합니다.(..